“Pandalar”, veri merkezli piton paketlerinden oluşan büyük ekosistemi nedeniyle veri analizini gerçekleştirmek için harika bir dildir. Bu, her iki faktörün analizini ve içe aktarılmasını kolaylaştırır. Standart sapma, ortalamadan türetilen 'tipik' bir sapmadır. Veri çerçevesinin orijinal ölçü birimlerini döndürdüğü için çok kullanılır. Pandalar standart sapmanın hesaplanması için std() kullandı. Standart sapma, veri çerçevesinde bir satır veya sütun şeklinde olabilen verilen değerlerden hesaplanabilir. Pandaların standart sapmasının kullanıldığı tüm olası yolları uygulayacağız. Kodun uygulanması için python dostu bir ortamda yazıldığı için “spyder” aracını kullanacağız.”
Sözdizimi
'df.std ( ) ”
Veri çerçevesindeki standart sapmayı hesaplamak için aşağıdaki sözdizimi kullanılır. Veri çerçevesindeki “df”, “veri çerçevesi”nin kısaltmasıdır. Standart sapma ne işe yarar? Gerekli verilerin ne kadar kapsamlı olduğunu ölçer. Genişletilmiş yüksek değerler ne kadar fazlaysa, standart sapma o kadar yüksek olmalıdır.
Dönüş
Seviye gereksinime göre belirtilirse, pandaların standart sapması veri çerçevesini döndürür.
'std()' işlevinin, pandaların standart sapmasını hesaplarken 'df'deki 'NaN' değerlerini otomatik olarak yok sayacağını unutmayın. “NaN”, belirli bir değere atanmış bir değer olmadığı anlamına gelen “sayı değil” olarak açıklanabilir.
Pandaların standart sapması örnekleriyle yürütülecek yöntemler şunlardır:
-
- Tek bir sütunda Pandalar standart sapma hesaplaması.
- Birden çok sütunda Pandalar standart sapma hesaplaması.
- Tüm sayısal sütunların Pandalar standart sapma hesaplaması.
- ekseni kullanarak pandaların standart sapması = 1.
- ekseni kullanarak pandaların standart sapması = 0.
Pandalarda Standart Sapmanın Hesaplanması için Veri Çerçevesi Oluşturma
İlk önce, “spyder” yazılımını açın. Şimdi pandalar kitaplığını pd olarak içe aktarın. “x”, “y” ve “z” terimlerinin “22”, “10”, “11”, “16”, “12”, “45” olduğu bir skorborddan oluşan bir dataframe oluşturacağız. ”, “36” ve “40”. Asist değerlerini “8”, “9”, “13”, “7”, “22”, “24”, “4” ve “6” olarak, ribaund değerleri ise “17”, “ 14”, “3”, 5”, “9”, “8”, “7” ve “4”.
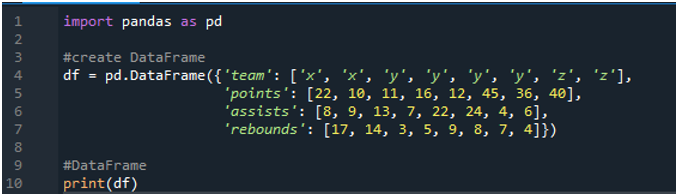
Ekranlar, kodda atanan değerlere göre oluşturulan veri çerçevesini gösterir:

Örnek # 01: Tek Bir Sütunda Pandalar Standart Sapma Hesaplaması
Bu örnekte, pandalar veri çerçevesindeki tek bir sütunun standart sapmasını hesaplayacağız. Dataframe, takımın 'u', 'v' ve 'b' değerlerine ve '44', '33', '22', '44', '45', '88', '96' puanlarına sahiptir. ” ve “78”. Asist değerleri “7”,”8”, “9”, “10”, “11”, “14”, “18” ve “17” olup ribaund değerleri ise “11”, “ 9”, “8”, “7”, “6”, “5”, “4” ve “3”. Tek sütunlu standart sapmayı hesaplamak için veri çerçevesinden 'noktalar' sütunu seçilir.
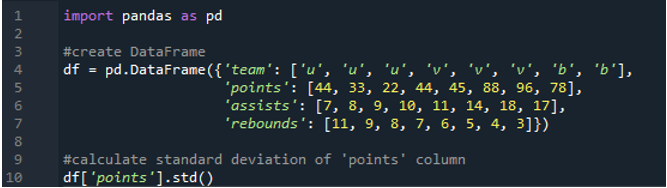
Çıktı, 'puan' sütununun hesaplanan standart sapmasını gösterir:

Örnek # 02: Çoklu Sütunlarda Pandalar Standart Sapma Hesaplaması
Bu örnekte, pandaların standart sapma hesaplamalarını birden çok sütunda gerçekleştireceğiz. Bu veri çerçevesinde yine takımın 'n', 'w' ve 't' değerlerine sahip spor skorbordunun verileri, skoru '33', '22', '66', '55', “44”, “88”, “99” ve “77”. Asistleri “9”, “7”, “8”, “11”, “16”, “14”, “12” ve “13”, ribaundlar ise “5”, “8”, “1”, “ 2”, “3”, “4”, “6” ve “7”. Burada, veri çerçevesine uygulanan std() işlevini kullanarak iki sütun “puan” ve “geri tepme”nin standart sapmasını hesaplayacağız.
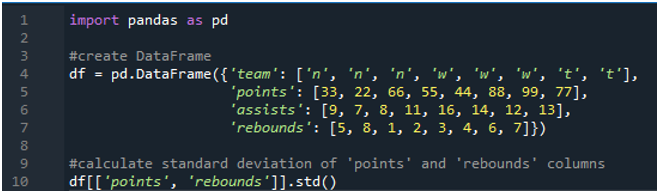
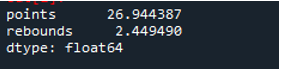
Gördüğümüz gibi, çıktı, standart sapmanın puan sütununda sırasıyla 26.944387 ve geri tepme sütununda 2.449490 olarak çıktığını göstermektedir.
Örnek # 03: Tüm Sayısal Sütunların Pandas Standart Sapma Hesaplaması
Şimdi tekli ve çoklu satırların standart sapmasını nasıl hesaplayacağımızı öğrendik. Veri çerçevesindeki tüm sütun adlarını belirtmek ve tüm veri çerçevesini hesaplamak istemiyorsak ne olur? Bu, sonuçlarda tüm veri çerçevesinin hesaplanması için pandaların standart sapmasının basit bir fonksiyon uygulamasıyla mümkündür. Buradaki veri çerçevesi, “33”, “36”, “79”, “78”, “58”, “55” puanlama değerlerine sahip “l”, “m” ve “o”dan oluşur ve iki takım aynı puanı alır. yani '25'. Asistleri “1”, “2”, “3”, “4”, “6”, “9”, “5” ve “7”, ribaundları ise “14”, “10”, “2” şeklindedir. , “5”, “8”, “3”, “6” ve “9”. Pandaların “std()” işlevini kullanarak veri çerçevesindeki pandalara göre tüm standart sütun sapmalarını hesaplayabiliriz.
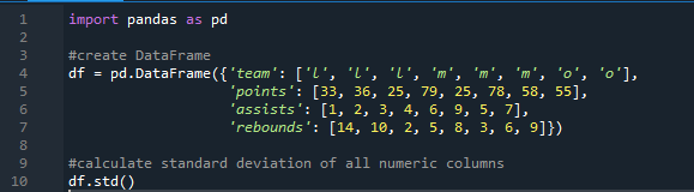
Ekran, aşağıda gösterilen tüm 'df'nin hesaplanmış standart sapmasına sahiptir; Ayrıca pandaların ilk sütun olan “takım”ın standart sapmasını sayısal bir sütun olmadığı için hesaplamadığını görebiliriz.
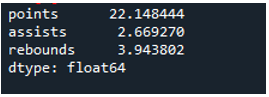
Örnek # 04: Ekseni Kullanan Panda Standart Sapması = 0
Bu örnekte, veri çerçeveleri spor takımlarını 'g', 'h' ve 'k' olarak ve daha fazla veriye sahiptir. Burada, pandaların standart sapmasında kullanılan bir parametre olan “0” eksenini kullanarak standart sapmayı hesaplayacağız. Bu argüman, veri çerçevesinin sütun bazında standart sapmasını hesaplar.
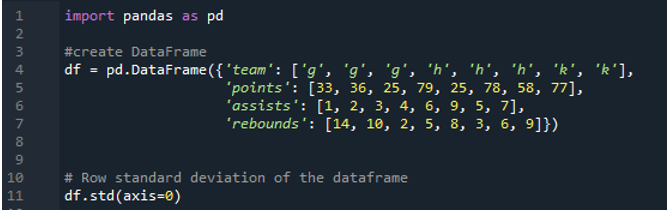
Aşağıdaki çıktı, hesaplanan standart sapmanın sütunlarındaki sonuçları görüntüler. Puan sütununda hesaplanan standart sapma “24.0313062”, destek sütununda hesaplanan standart sapma “2.669270” ve geri tepme sütununun hesaplanan standart sapması “3.943802” olarak gösterilir.
Örnek # 05: Ekseni Kullanan Panda Standart Sapması = 1
Burada pandalarda standart sapmayı hesaplamak için “1” olarak atanan eksen parametresini kullanacağız. “1” ekseni ne gibi bir fark yaratabilir? “1” ekseni argümanı, veri çerçevesindeki sayısal değerlerin satır bazında standart sapmasını hesaplar. Veri çerçevesi, takımın puanları, takımın asistleri ve takımın ribaundları olarak oluşturulan veri sütunlarının eklenmesiyle “s”, “d” ve “e” olarak üç takımı içerir. Yönlerin tümü, veri çerçevesinde farklı değerlerle atanır. Bu eksen parametresi öyle bir oyun değiştiricidir ki, zamanla, bir sütun artı gerçekleştirilen standart sapmanın hesaplanan noktasında olmasını istediğimiz veriler üzerinde çalışmamız gerekir.
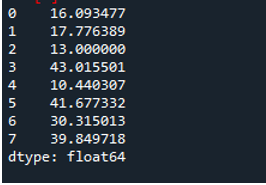
Aşağıdaki çıktı, veri çerçevesinin bir satırında hesaplanan standart sapmayı gösterir:
Çözüm
Pandaların standart sapması, pandaların veri çerçevelerinin coşku anlaşmasının standart sapmasını bulduğu için çok faydalı bir işlev olan çok teknik bir işlevdir. Bu başyazıda, pandalarda standart sapmayı hesaplama yöntemlerini inceledik. Tek sütunlu standart sapma ve çoklu sütun hesaplamaları yaptık ve ayrıca tüm veri çerçevesinin standart sapmasını birlikte hesapladık. Tüm stratejiler, tutarlı ve istenen sonuçlarla kullanıldıkları sürece iyi çalışır.