Şimdi terminal konsolunda Linux'un iconv yardımcı programına bakalım. Bu nedenle, terminal ekranımızda bilinen ve en çok kullanılan tüm kodlanmış karakter setlerini görüntülemek için “-l” bayrağıyla “iconv” komutunu uyguluyoruz. Kodlanmış karakter kümelerini takma adlarıyla birlikte görüntüler. Biraz aşağı kaydırdıktan sonra uzun bir kodlanmış karakter kümeleri listesi görebilirsiniz.
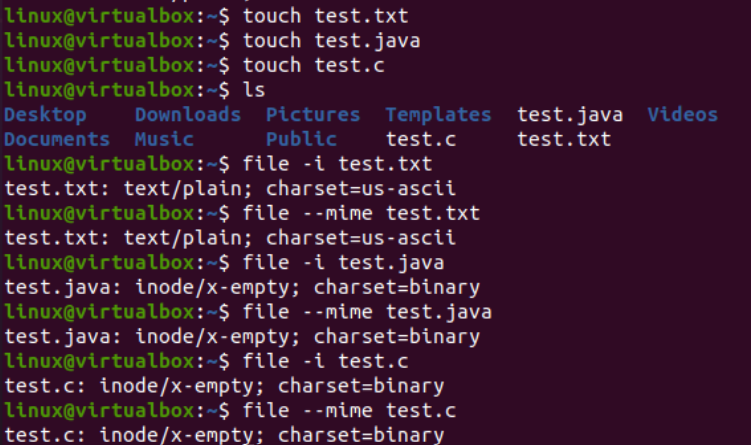
Şimdi, iconv komutunun Linux'ta uygulanmasına başlamanın zamanı geldi. İlk olarak, bir dosya türünü başka bir türe dönüştürmek için sistemimizde farklı dosya türlerine ihtiyacımız var. Bu nedenle, Java tipi, C tipi ve metin tipi olmak üzere üç farklı dosya oluşturmak için konsol terminalinde “dokunma” sorgusunu kullanıyoruz. Geçerli dizin içeriğini listeleyerek, içinde yeni oluşturulan dosyaları bulacaksınız.
Bundan sonra, her dosyanın adı ile birlikte “dosya” sorgusunu kullanarak her dosyanın türüne ayrı ayrı bakacağız. Bu sorgu, her dosya için ayrı ayrı kodlama karakter kümesinin türünü görüntülemek için “-I” seçeneğine ihtiyaç duyar. “-I” seçeneğini kullanmayı unuttuysanız, bunun yerine “—mime” bayrağını kullanın. Hem “-I” hem de “—mime” bayrakları aynı şekilde çalışır.
Şimdi “txt” tipi dosya için “file” komutunu çalıştırdıktan sonra “US-ASCII” karakter tipi kodlamasını aldık. Java ve C dosyaları için aynı talimatı kullanırken, her iki dosyanın da “BINARY” karakter tipi kodlaması içerdiğini gösterir. Bununla birlikte, bu talimat, bu üç dosyanın da boş olduğunu gösterir.
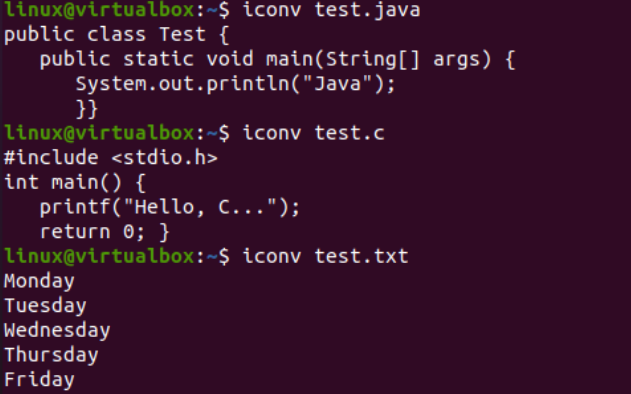
Şimdi, belirli bir karakter seti kodlama dosyasını başka bir karakter seti kodlamasına dönüştürmek için konsolda iconv komutunun kullanımını göstereceğiz. Bundan önce, dosyalarımıza bazı kodlar veya veriler eklemeliyiz. Bu nedenle Java kodunu “text.java” dosyasına, C kodunu “text.c” dosyasına ekledik ve metin verilerini “test.txt” dosyasına ekledik. Cat sorgusu, aşağıda gösterildiği gibi, üç dosyanın da içeriğini görüntülemek için burada kullanıldı:
Artık verileri başarıyla eklediğimize göre, bu dosyaların karakter seti kodlamasını bir kez daha göreceğiz. Bu nedenle, aynı dosya talimatını “-I” bayrağı ve dosya isimleri, yani test.txt, test.java ve test.c ile kabuk içinde denedik. Bu üç talimatın üç dosya için ayrı ayrı çalıştırılması, karakter seti kodlamasının Java ve C dosyaları için güncellendiğini, metin dosyası, yani US-ASCII için aynı kaldığını gösterir. Java ve C dosyalarının kodlaması önceden “ikili” idi; şimdi, 'US-ASCII'. Ayrıca, metin dosyasının düz metin verilerini içerdiğini, diğer iki kod dosyasının ise içerik olarak komut dosyalarını içerdiğini gösterir.

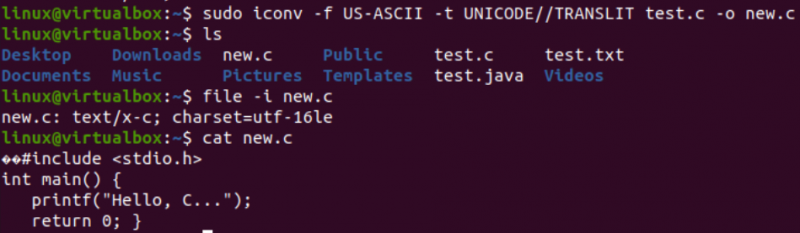
Bu makale için gereken asıl görevi gerçekleştirmenin, yani kabuktaki iconv komutunu kullanarak bir kodlamayı diğerine dönüştürmenin zamanı geldi. Bu nedenle, kabuk terminali içindeki 'iconv' komutunu 'sudo' ayrıcalıklarıyla kullanıyoruz. Bu komut, '-f' seçeneğinin 'from' anlamına geldiğini ve '-t' seçeneğinin 'to' anlamına geldiğini, yani bir kodlamadan diğerine geçtiğini alır.
“-f” seçeneğinden sonra dosyanızın zaten sahip olduğu kodlamayı belirtmelisiniz, yani US-ASCII. “-t” seçeneğinden sonra ise eski kodlama ile değiştirmek istediğiniz kodlamayı yani UNICODE'u belirtmelisiniz. Nesne görüntüsünü oluşturmak için –o seçeneğiyle kaynak olarak kullanılan bir dosyanın adını belirtmeniz gerekir. Nesne görüntüsü, aynı türden ancak yeni kodlamaya ve aynı verilere sahip başka bir dosya, yani 'new.c' olacaktır.
Aşağıdaki yönergeyi uyguladıktan sonra aynı dizinde yani “ls” sorgusuna göre yeni bir dosya alacaksınız. Şimdi iconv komutu kullanılarak oluşturulan yeni bir dosyanın karakter seti kodlamasını kontrol edeceğiz. “-I” seçeneği ve yeni dosya adı, yani new.c ile “file” komutunu tekrar kullanacağız.
Bu yeni dosyanın karakter setinin eski bir dosyanın karakter setinden, yani UTF-16LE karakter setinden farklı olduğunu göreceksiniz. Bunun nedeni, yeni.c dosyamız için iconv komutunu kullanarak US-ASCII kodlamasını UNICODE kodlamasına çevirmiş olmamızdır. 'Kedi' sorgusu, dosya içinde aynı C kodunu görüntüledi, ancak daha önce sunulduğu gibi bazı Unicode karakterleriyle başladı.
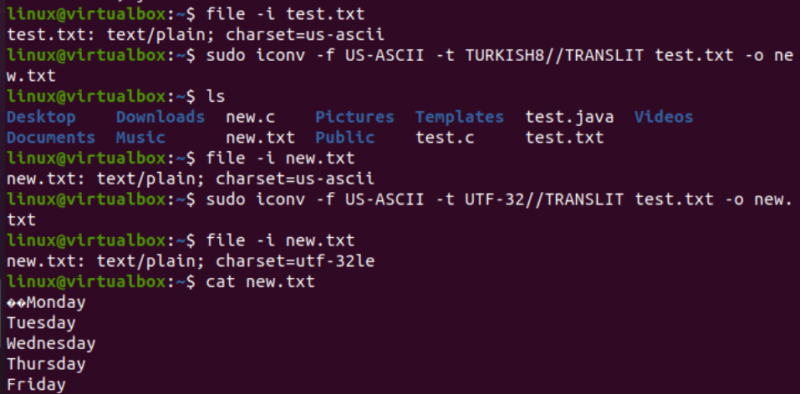
Çok benzer bir şekilde, test.txt metin dosyasının kodlamasını değiştireceğiz. Dosya talimatı, bir US-ASCII karakter seti kodlamasına sahip olduğunu gösterir. iconv komutu, test.txt dosyasının kodlamasını US-ASCII'den TURKISH8'e dönüştürmek için aynı formatta kullanılmıştır. US-ASCII'yi Türkçe'ye çevirmediğini göreceksiniz.
Bundan sonra, aynı dosya için US-ASCII - UTF-32 karakter seti kodlamasını kapsayacak şekilde aynı komutu kullandık. Bu sefer işe yarıyor. Bunun nedeni, bazen bir kodlama kümesini diğerine dönüştürürken bir sorun olabilmesi veya diğer kodlamanın bunu desteklememesi olabilir.
Çözüm
Bu makale, takma adlarını kullanarak bir kodlama karakter kümesini diğerine dönüştürmek için iconv Linux talimatlarının nasıl kullanılacağını tartıştı. Bu şekilde, farklı türlerde bazı dosyalar oluşturmak zorunda kaldık.